강화학습을 혼자서 책만 보고 공부하는 것은 힘들다.
다양한 매체들을 이용해 공부를 시작해보자. 첫번째로 홍콩과기대 김성훈 교수님의 모두를 위한 RL 강좌를 보고 내용을 정리하며 공부.
강의 유튜브: https://www.youtube.com/user/hunkims/featured

Lecture 1: 강화학습 소개

Reinforce라는 개념은 머신러닝뿐만 아니라 여러분야에서도 사용된다. 예를 들어 개를 훈련킬 때 Positive Reinforcement를 사용할 수 있는데, 개가 잘하면 거기에 맞는 reward를 주는 방식으로 개를 훈련시킬 수 있다.
사실 reinforce라는 아이디어는 우리가 그동안 학습해오던 모든 것들과 비슷하다. 우리는 환경과의 상호작용을 통해 칭찬을 받는다던지 그 밖의 부정적인 것을 받는다던지 이런 것들을 통해 학습했다. 이걸 머신러닝에 적용한 것이 강화학습에 기본 아이디어다.

여기서 우리가 살아가는 세상을 환경(Environment)라 하고 환경에서 행동을 하는 에이전트를 Actor라 한다. 그리고 에이전트가 하는 행동을 action이라 한다. 에이전트가 이런 행동을 할 때마다 환경에서 상태(observation)가 변경된다. 그림을 예로보면, 쥐는 이런 많은 행동을 통해 미로를 탐험하며 최종족으로 치즈를 reward로 받는 것이다.

사실 강화학습 알고리즘은 오래된 알고리즘인데 최근 아타리 게임을 통해 화려하게 부활했다. 여기서 강화학습 에이전트는 사람보다 더 게임을 잘한다.
사람의 경우 우리의 눈을 통해 게임에서 픽셀정보를 받아들여 조이스틱을 조작한다. 아타리 게임을 학습하는 에이전트도 마찬가지인데 다만 뇌를 통해 학습하는 사람과는 다르게 픽셀과 조이스틱의 중간에 RL 알고리즘을 사용해 학습시키고 그 학습의 결과로 어디로 움직일지(조이스틱 조작)를 정하는것이다.
그 밖의 강화학습은 로봇의 관절의 움직임, 재고 관리, 주식 등 활용의 범위가 매우 넓다.

Lecture 2: 우리는 actor가 어떤 action을 할 것인가를 알고리즘을 통해 학습시킬 것인데 OpenAI GYM을 활용해 학습시킬 것이다.
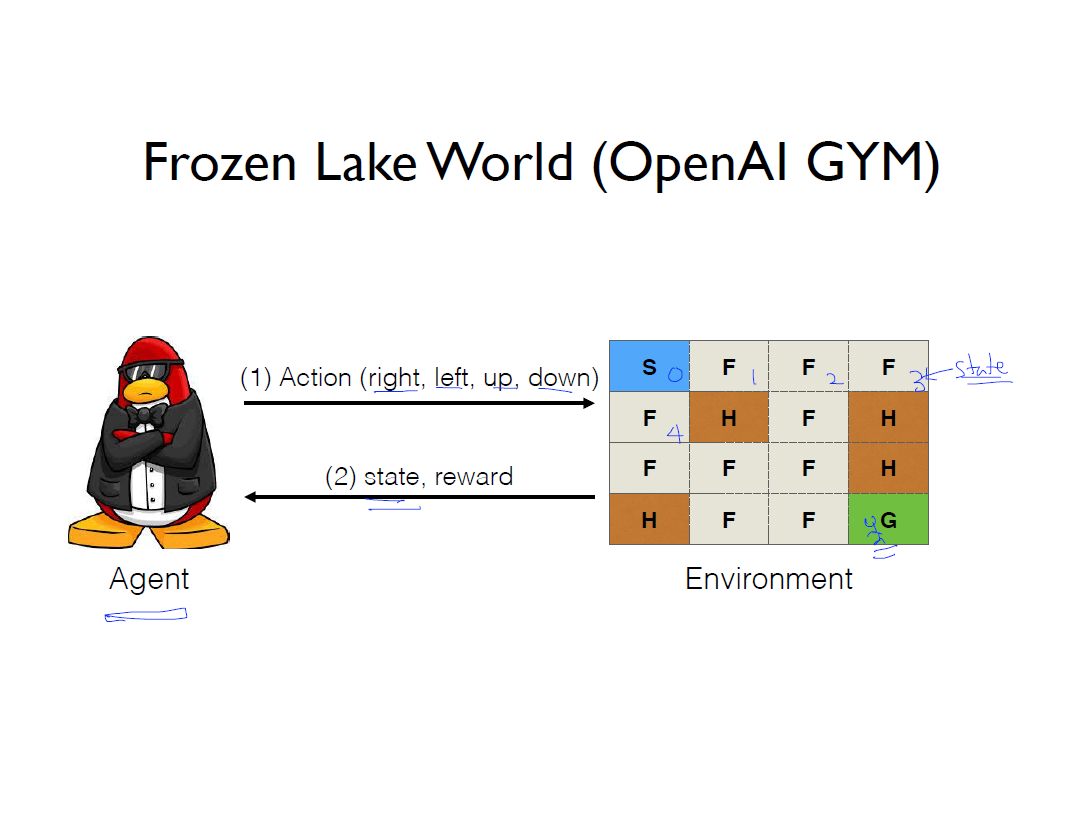
우리는 OpenAI GYM에서 frozen lake라는 환경을 이용할 것이다. S는 에이전트가 시작하는 부분이고 F의 경우 얼음이 있는 곳, H는 구멍으로 거기에 에이전트가 가면 빠져서 게임은 끝난다. 그리고 G는 에이전트가 도착하고자 하는 골으로 에이전트는 어떻게하면 골에 갈 수 있는지 고민할 것이다.
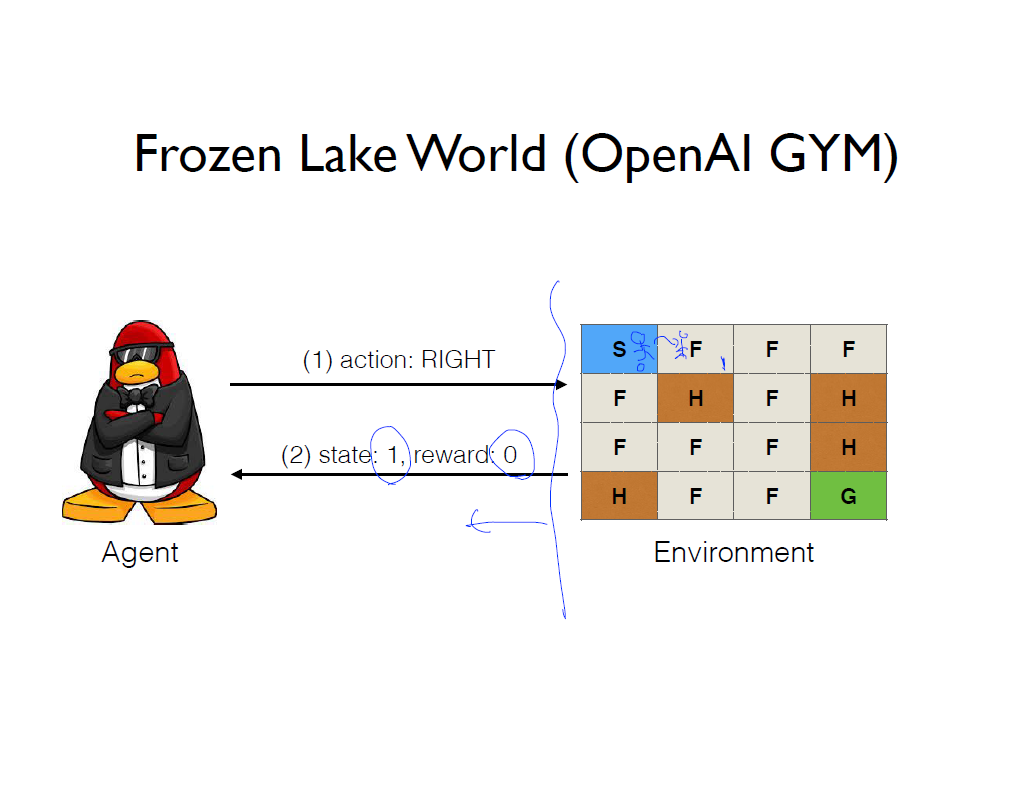
에이전트는 환경 내에서 돌아 다니는데 현재 frozen lake 환경에서 에이전트가 할 수 있는 행동은 상, 하, 좌, 우 4가지 이고, 행동을 하면 환경은 에이전트에게 그에 맞는 상태를 되돌려 준다. 그리고 에이전트는 골에 도달하면 reward를 받는다. 만약 그림에서 처럼 상태 0에서 오른쪽 행동을 선택해 상태 1로 가면, 환경은 그에 따른 에이전트의 현재 상태 1을 알려줄 것이고 거기에 맞는 reward는 0이다라는 것을 알려줄 것이다.

OpenAI를 사용하는 방법은 매우 간단한데
그림에서 처럼 gym.make()로 환경을 만들어주고
env.reset()으로 환경을 초기화한다. 그리고 초기화된 state(observation)을 가져온다.
env.render()는 환경을 출력해준다.
그리고 에이전트가 학습한 알고리즘에 따라 action을 선택할 것이고
그 action은 env.step(action)으로 환경 내에서 action을 선택한다. 그리고 action의 결과로 observation, reward, done, info의 정보를 얻는다. 여기서 done은 hole 또는 goal에 가면 게임이 끝나기 때문에 이 경우에 true가 될 것이다.

다만 실제 에이전트의 입장에서는 환경이 하나도 보이지 않는다. 내가 오른쪽으로 가든 아래로 가든 거기에 구멍이 있는지 아니면 얼어있는 표면이 있는지 알수가 없다는 말이다. 실제로 에이전트는 이렇게 시작점은 아는데 예를 들어 오른쪽으로 가면 뭐가 있는지도 모르는 상태로 게임을 시작한다.

Lab 2: 실제로 코딩을 해보자.

강의에 나온 사용자의 키 입력을 받아 들일 수 있는 코드는 위와 같은데, 윈도우 환경에서는 저 코드는 작동하지 않는다. 그래서 https://altongmon.tistory.com/703 이 링크에 나온 내용을 참고해 윈도우에 맞게 코드를 수정해준다.
# MACROS
LEFT = 0
DOWN = 1
RIGHT = 2
UP = 3
# Key mapping
arrow_keys = {
b'H' : UP,
b'P' : DOWN,
b'M' : RIGHT,
b'K' : LEFT}
class _Getch:
def __call__(self):
keyy = msvcrt.getch()
return msvcrt.getch()

위의 코드를 수정해줬으니 당연히 여기 코드도 수정해 준다. sys, tty, termios 대신에 import msvcrt만 사용했음을 알 수 있다.
import gym
from gym.envs.registration import register
import msvcrt
# Register FrozenLake with is_slippery False
register(
id='FrozenLake-v3',
entry_point='gym.envs.toy_text:FrozenLakeEnv',
kwargs={'map_name' : '4x4', 'is_slippery': False}
)
env = gym.make('FrozenLake-v3')
env.render()
inkey = _Getch()
while True:
#Choose an action from keyboard
key= inkey()
print(key)
if key not in arrow_keys.keys():
print("Game aborted!")
break
action = arrow_keys[key]
state, reward, done, info = env.step(action)
env.render()
print("State: ", state, "Action: ", action, "Rewrad: ", reward, "Info: ", info)
if done:
print("Finiished with reward", reward)
break
그리고 실행시켜본 결과.
요상하게 표현되는 곳이 있긴한데 그냥 에이전트의 현재상태라고 보면된다.

Reference
[1] http://hunkim.github.io/ml/
[2] Lecture 1
[3] Lecture 2
[4] Lab2
'강화학습 > RL 강의 정리' 카테고리의 다른 글
| 모두를 위한 RL강좌 정리하기(Lecture7 ~ Lab7) (4) | 2020.08.30 |
|---|---|
| 모두를 위한 RL강좌 정리하기(Lecture 6 ~ Lab 6) (4) | 2020.08.28 |
| 모두를 위한 RL강좌 정리하기(Lecture 5 ~ Lab 5) (0) | 2020.08.16 |
| 모두를 위한 RL강좌 정리하기(Lecture 4 ~ Lab 4) (0) | 2020.08.12 |
| 모두를 위한 RL강좌 정리하기(Lecture 3 ~ Lab 3) (0) | 2020.08.11 |