
앞에서는 큐네트워크를 이용해 CartPole문제를 풀려고 했지만 잘 풀리지 않는 것을 보았다. 그건 강화학습+신경망의 문제 때문인데 그 문제는 각 샘플들간의 상관관계와 target이 유동적이기 때문이다. 이 두개가 정말 큰 문제이다. 근데 DQN을 만든 딥마인드는 이 문제들을 풀어냈고 이 것들을 어떻게 풀어냈는지 보자.

일단 첫번째로 샘플들간의 상관관계가 있는데 내가 카트폴을 training 시킨다고 했을 때, 카트폴이 움직일 때 정말 조금조금씩 움직이므로 이렇게 연속적으로 받은 데이터들은 굉장히 유사할 것이다. 그래서 이 데이터(샘플)들 간에 연관성이 있다는 얘기이다.

예를 들어 데이터의 분포가 위와 같을 때 인접한 데이터들끼리만 학습을 시킨다고 하면 그림처럼 전체 데이터와는 아주 다르게 학습을 할 것이다. 큐네트워크에서는 이런 샘플들간의 상관관계를 해결해야 한다.

두번째로는 이 y(label)값이 계속 변하는 것이다. 예측과 정답이 같은 신경망을 공유하기 때문에 학습하며 신경망을 업데이트하면 정답도 같이 변하게 되는 것이다. 이 문제도 해결을 해야 한다.

DQN에서는 학습을 더 잘하게 하기 위해 다음과 같은 세가지 솔루션을 제시했다. 1. 더 깊게 만들기 2. capture and replay 3. 네트워크 분리

첫번째로 더 깊은 신경망은 CNN 네트워크로 말그대로 신경망을 더 쌓으면 된다.


두번째로 샘플들간의 상관관계를 해결하는 법은 일단 샘플들을 수집해 저장을 해놓고 여기서 랜덤하게 샘플들을 몇개 뽑아 배치로 학습시키는 것이다. 그러면 아래의 그림처럼 상관관계가 없는 데이터들로 학습을 시켜 전체데이터와 유사하게 학습을 할 수 있다.

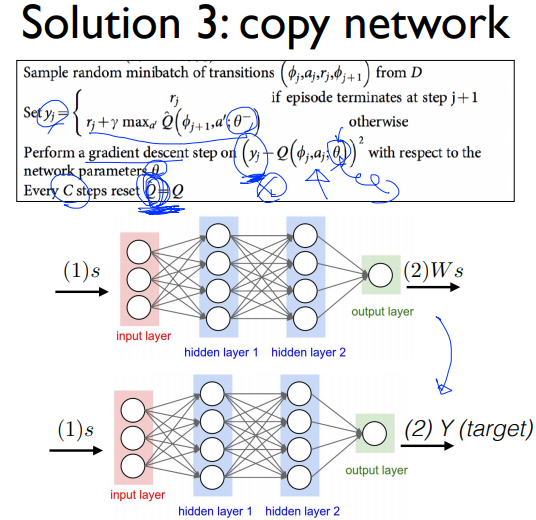
세번째는 y값이 계속 변하는 문제였다. 여기서는 이 문제를 해결하기 위해 target network를 분리시킨다. 그림처럼 Q값을 예측하는 네트워크와 target을 알려주는 네트워크를 따로 두는 것이다. 그러면 원래 네트워크를 업데이트해도 타겟 네트워크에는 변화가 없어 stationary target이 된다.
원래 네트워크를 계속 학습시키면서 사전에 정한 C step이 되면 원래 네트워크를 타겟 네트워크로 복사한다.

이 전체적인 DQN 알고리즘을 보면 리플레이 메모리를 만들고 Q 네트워크를 초기화시키고 타겟 Q 네트워크에 그 값을 복사한다. 각 state가 들어오면 전처리를 하고 action을 선택, reward를 받고, 다음 state도 전처리를 해서 리플레이 메모리에 넣는다. 리플레이 메모리에 어느정도 데이터가 쌓이면 미니배치로 Q네트워크를 업데이트한다. C step마다 업데이트한 Q네트워크를 타겟 네트워크에 복사한다.
다음은 이를 구현한 코드를 보자
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import random
from collections import deque
import gym여기서는 리플레이 메모리를 위해 deque이라는 자료구조를 사용한다.
env = gym.make("CartPole-v0")
env._max_episode_steps=10001
input_size = env.observation_space.shape[0]
output_size = env.action_space.n
dis = 0.9
REPLAY_MEMORY = 50000카트폴 예제의 경우 최대 스텝이 200으로 제한되어 있는데 이 스텝을 10001으로 늘린다.
class DQN:
def __init__(self, input_size, output_size, name="main"):
self.input_size = input_size
self.output_size = output_size
self.net_name = name
self._build_network()
def _build_network(self, h_size=10, l_rate=1e-1):
self._model = tf.keras.Sequential([
tf.keras.layers.Dense(10, input_shape=[self.input_size], activation=tf.nn.tanh),
tf.keras.layers.Dense(output_size)
])
self._model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=l_rate),
loss='mse')
self._model.summary()
def predict(self, state):
x = np.reshape(state, [1, self.input_size])
return self._model.predict(x)
def update(self, x_stack, y_stack):
hist = self._model.fit(x_stack, y_stack, verbose=0)
return hist
def get_weights(self):
return self._model.get_weights()
def set_weights(self, src_model):
return self._model.set_weights(src_model.get_weights())강의에서는 DQN네트워크를 클래스로 구현했다.
kears를 이용해 구현했고 강의에서 나온 코드와 좀 다르게 생겼지만 노드가 10개가 있는 히든레이어가 하나 있고 activation function으로 tanh를 사용해 차이는 없다. 강의에서는 xavier initializer를 사용했는데 Dense의 initializer의 초기값이 xavier였으므로 굳이 다시 파라미터로 넣지는 않았다.
update의 경우도 hist로 리턴을 시키게 했다. hist에는 loss, accuracy등이 저장되어 있다.
그 밖의 코드들은 지난번에 구현한 것들과 비슷한데 get_weights()와 set_weights()는 모델을 클래스로 구현했으므로 각 모델을 복사하기 위해 필요해 추가했다.
def get_copy_var_ops(dest_model, src_model):
dest_model.set_weights(src_model)원래 모델의 weights를 타겟 모델로 복사하는 함수이다. 즉 모델을 복사한다.
def replay_train(mainDQN, targetDQN, train_batch):
x_stack = np.empty(0).reshape(0, mainDQN.input_size)
y_stack = np.empty(0).reshape(0, mainDQN.output_size)
for state, action, reward, next_state, done in train_batch:
Q = mainDQN.predict(state)
if done:
Q[0, action] = reward
else:
Q[0, action] = reward + dis*np.max(targetDQN.predict(next_state))
y_stack = np.vstack([y_stack, Q])
x_stack = np.vstack([x_stack, state])
return mainDQN.update(x_stack, y_stack)모델들과 minibatch를 인풋으로 받아 학습시키는 코드이다.
두개의 신경망(mainDQN, targetDQN)과 minibatch를 인풋으로 받고, 리플레이 메모리에 저장한 샘플들의 state를 targetDQN에 넣어서 label을 얻고 신경망을 minibatch로 학습시키기 위해 state와 label에 해당하는 Q값들을 스택으로 쌓는다.
def bot_play(mainDQN):
s = env.reset()
reward_sum=0
while True:
env.render()
a = np.argmax(mainDQN.predict(s))
s, reward, done, _ = env.step(a)
reward_sum += reward
if done:
print("Total Score: {}".format(reward_sum))
break
env.close()이건 훈련시킨 모델을 직접 실행시켜서 눈으로 보는 코드다. env.render()를 통해 그림을 그린다.
def main():
max_episodes = 5000
replay_buffer = deque()
mainDQN = DQN(input_size, output_size, name="main")
targetDQN = DQN(input_size, output_size, name="target")
get_copy_var_ops(dest_model=targetDQN, src_model=mainDQN)
for episode in range(max_episodes):
e = 1. / ((episode / 10)+1)
done = False
step_count = 0
state = env.reset()
while not done:
if np.random.rand(1) < e:
action = env.action_space.sample()
else:
action = np.argmax(mainDQN.predict(state))
next_state, reward, done, _ = env.step(action)
if done:
reward = -100
replay_buffer.append((state, action, reward, next_state, done))
if len(replay_buffer) > REPLAY_MEMORY:
replay_buffer.popleft()
state = next_state
step_count +=1
if step_count > 10000:
break
print("Episode: {} steps: {}".format(episode, step_count))
if step_count > 10000:
pass
if episode % 10 == 1:
for _ in range(50):
minibatch = random.sample(replay_buffer, 10)
hist = replay_train(mainDQN, targetDQN, minibatch)
print("Loss: ", hist.history["loss"])
get_copy_var_ops(targetDQN, mainDQN)메인코드 부분이다. mainDQN과 targetDQN을 따로 생성하고 모델을 복사한다. 나머지 코드들은 그 전에 구현한 것과 유사한데 몇가지 다른 부분이 있다.
리플레이 버퍼에 수집한 샘플들을 담고 10번째 에피소드마다 미니배치학습을 진행한다. 리플레이 버퍼에서 10개의 샘플을 무작위로 뽑고 이를 학습시킨다. 근데 이를 50번 반복하니까 총 500개의 샘플을 무작위로 뽑아서 학습시키는 것이라고 할 수 있을 것 같다. 그리고 학습한 후에는 mainDQN을 targetDQN으로 복사한다.

다음은 학습과정인데 대충 400번부터 step이 10001이라서 이정도면 학습이 꽤 잘 된 것 같다.
결론적으로 큐네트워크에서 더 깊은 신경망 + 리플레이 메모리 + 타겟네트워크를 한 것이 DQN이고 여기서 중요한 것은 리플레이 메모리와 타겟네트워크라고 할 수 있다.
Reference:
[1]: hunkim.github.io/ml/
[2]: youtu.be/S1Y9eys2bdg
[3]: youtu.be/Fbf9YUyDFww
[4]: youtu.be/ByB49iDMiZE
'강화학습 > RL 강의 정리' 카테고리의 다른 글
| 모두를 위한 RL강좌 정리하기(Lecture 6 ~ Lab 6) (4) | 2020.08.28 |
|---|---|
| 모두를 위한 RL강좌 정리하기(Lecture 5 ~ Lab 5) (0) | 2020.08.16 |
| 모두를 위한 RL강좌 정리하기(Lecture 4 ~ Lab 4) (0) | 2020.08.12 |
| 모두를 위한 RL강좌 정리하기(Lecture 3 ~ Lab 3) (0) | 2020.08.11 |
| 모두를 위한 RL강좌 정리하기(Lecture 1 ~ Lab 2) (0) | 2020.05.25 |