가치함수
에이전트가 어떤 정책이 더 좋은 정책인지 판단하는 기준, 현재 선택한 정책에서 예상되는 보상의 합
하나의 에피소드를 진행할 때
현재 시점 t에서 에이전트가 어떤 행동을 하면서 받을 보상을 다 합치면 다음과 같이 표현 가능

현재 받을 보상과 나중에 받을 보상은 다르기 때문에 감가율을 고려해 시간이 지날수록 받는 보상은 감소, 이를 반환값 G로 표현, 반환값은 에이전트가 에피소드를 끝낸 후 실제로 받은 과거의 보상들을 정산한 것

어떠한 상태에 있을 때 앞으로 얼마의 보상을 받을 것인지에 대한 기대값이 가치함수, 상태 S에서 반환값 G의 기대값으로 표현, 에이전트는 가치함수가 제일 높은 상태를 선택

위의 식들을 이용해 가치함수를 다음과 같이 표현 가능

but 에이전트가 실제로 받은 보상이 아닌 앞으로 받을 것이라 예상되는 보상이기 때문에 반환값 G를 다르게 표현

여기서 에이전트의 정책을 고려하면 정책을 고려한 가치함수가 나옴, 벨만 기대 방정식 = 현재 상태의 가치함수와 다음 상태의 가치함수 사이의 관계
정책이란 상태 s에서 행동들을 할 확률이라 할 수 있음
벨만 기대 방정식
어떤 정책을 따라 갔을 때 가치함수 사이의 관계식

기대값으로 표현된 벨만 기대 방정식을 계산 가능한 형태로 바꾸면
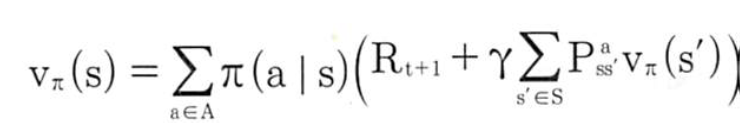
1. 상태 s에서 행동 a를 확률(정책 파이)
2. 그 행동 a를 했을 때 받는 보상 R
3. 상태 s에서 행동 a를 했을 때 다음 상태의 가치함수
1번 X (2번 + 3번)
상태 s에서 가능한 모든 행동 a에 계산하고 모두 더하면 정책에 대한 가치함수가 나옴
벨만 기대 방정식을 계속 계산하면 현재 정책 파이에 대한 참 가치함수를 구할 수 있음, 참 가치함수란 현재 정책을 따라 움직였을 경우 받는 보상에 대한 참값
이 참 가치함수를 모든 상태에 대해서 동시에 전부다 구함
그리고 최적 가치함수라는게 존재, 최적 가치함수는 수 많은 정책 중 가장 높은 보상 주는 가치함수
참 가치함수라고 해서 최적 가치함수는 아님
그래서 더 좋은 정책으로 업데이트 해야함
큐함수
에이전트가 선택한 행동의 가치를 직접적으로 나타냄
여기서 잠깐 큐함수라는 것이 있음, 앞에 것은 상태의 가치함수
어떤 상태에서 어떤 '행동'이 얼마나 좋을까는 행동 가치함수로 표현, 이게 큐함수
그래서 큐함수는 상태와 행동 두가지 변수를 갖음
가치함수와 큐함수 사이의 관계, 상태 s에서 행동 a를 할 확률에 상태 s에서 행동 a를 했을 때 받을 보상인 큐함수를 곱한 것을 상태 s에서 할 수 있는 모든 행동 a를 더한 것이 가치함수

큐함수도 벨만 기대 방정식 형태로 나타내면 상태 s, 행동 a일 때 현재 큐함수와 다음 큐함수와의 관계는

벨만 최적 방정식
최적의 가치함수를 받게하는 정책
앞의 벨만 기대 방정식을 이용해 어떠한 정책에 대한 참 가치함수를 구할 수 있고 이는 최적 가치함수와는 다를 수 있음을 말함, 내가 찾고 싶은 것은 수 많은 정책 중 가장 높은 보상을 주는 최적 가치함수
모든 정책에 대해 가장 큰 가치함수를 주는 정책이 최적 정책, 최적 정책을 따라 갔을 때 받을 보상의 합이 최적 가치함수

최적 큐함수도 같은 방식으로 구함

가장 높은 가치함수를 찾았을 때, 그 때의 최적 정책은 각 상태 s에서 큐함수 중 가장 큰 큐함수를 가진 행동
그러니까 최적 정책은 큐함수 중에서 가장 높은 값을 가지는 행동을 선택, 최적 정책은 큐함수만 알면 구할 수가 있게 됨
위에 써진 최적 가치함수를 큐함수에 대해서 쓰면

상태 s, 행동 a 일때 큐함수 중 최대 값을 구하는게 최적 가치함수가 된다는 말, 안의 큐함수를 가치함수로 고쳐쓰면 벨만 최적 방정식이 됨

그리고 큐함수에 대해서도 벨만 최적 방정식으로 표현 가능, 큐함수를 가치함수로 바꿔 쓰면 벨만 최적 방정식이 됨

최적 정책에서는 현재 상태의 큐함수는 다음 상태에서 선택가능한 행동 중 큐함수 값이 가장 높은 것과 보상 R을 더한 것이라고 표현
기대값 E를 사용하는 이유는 환경에서 주는 값이므로
참고 : 파이썬과 케라스로 배우는 강화학습
http://www.yes24.com/Product/Goods/44136413?scode=032&OzSrank=5
'강화학습' 카테고리의 다른 글
| [강화학습] 딥살사, 폴리시 그레디언트 (0) | 2020.01.18 |
|---|---|
| [강화학습] 살사, 큐러닝 (0) | 2020.01.18 |
| [강화학습]다이내믹 프로그래밍 (0) | 2020.01.15 |