다이내믹 프로그래밍에서의 한계는 1. 계산 복잡도, 2. 차원의 저주 3. 환경에 대한 정보 이 세가지
몬테카를로 예측, 살사, 큐러닝에서는 3번 문제만 해결했음 1, 2번 문제를 해결하기 위해 다른 방법이 필요
인공신경망을 사용하자, 기존의 살사 알고리즘의 큐함수를 인공신경망으로 근사 --> 딥살사
살사의 큐함수 업데이트식은 이랬음
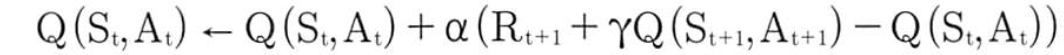
딥살사에서 인공신경망의 업데이트는 경사하강법 이용, 오차함수는 MSE를 사용
강화학습은 지도학습이 아니라 정답이 없으므로 정답으로 살사의 큐함수 업데이트에서 정답 역할을 하던 것을 정답으로 사용, 그게 바로 이 식

그리고 예측 역할을 하던 것은

이제 정답과 예측을 MSE에 집어넣어 오차함수를 만들기

이제 큐함수를 근사하는 인공신경망을 오차함수 MSE를 통해 업데이트 시킬 수 있음 이게 바로 학습시키는 것
딥살사에서 입실론-팀욕정책의 입실론은 시간에 따라 감소시킴, 초반에는 에이전트가 다양한 상황에 대해 학습, 후반에는 예측한대로 움직이게 하기 위해
폴리시 그레디언트
지금까지의 강화학습은 가치 기반 강화학습, 에이전트가 가치함수 기반으로 행동을 선택하고 가치함수를 업데이트 시킴
정책 기반 강화학습은 가치함수 토대로 행동을 선택하지 않고 상태에 따라 바로 행동을 선택
딥살사 : 인공신경망이 큐함수를 근사
정책 기반 강화학습 : 인공신경망이 정책을 근사
정책 근사 인공신경망 : 정책신경망 사용, 딥살사와 출력층이 다름
활성화 함수도 딥살사와 정책 신경망은 다름
딥살사 : 선형함수
정책 신경망 : softmax, 0~1사이의 값 출력
softmax는 출력층의 출력이 다 합해서 1이 나옴, 이게 바로 정책의 정의로 상태에서 각 행동을 할 확률을 나타냄
딥살사에서는 MSE로 오차를 줄이면서 학습하는데 정책 기반 강화학습에서는 MSE를 사용하지 않음
강화학습의 목표는 누적 보상을 최대로 하는 최적 정책을 찾는 것인데 정책 신경망을 사용할 경우 정책 신경망의 가중치값에 따라 에이전트가 받을 누적 보상이 달라짐
그러니까 정책 신경망의 가중치값은 누적보상이라는 함수의 변수
정책 신경망에 따른 정책을 다음과 같이 표현

정책 신경망의 가중치 값이 정책 대체 θ
그리고 누적보상은 최적화하고자 하는 목표함수 J(θ), 변수는 인공신경망의 가중치인 θ
이를 최대화해야 하므로 다음과 같이 표현

목표함수 J는 목표함수를 미분해 미분값에 따라 정책을 업데이트해 최적화 시킴, 근데 딥살사와는 다르게 목표함수가 오류함수 최소화가 아닌 목표함수 최대화이니 경사는 올라감 --> 경사상승법 사용
경사상승법에 따른 정책신경망 업데이트를 수식으로 나타내면
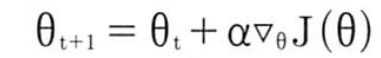
t+1 시각에서 정책 신경망의 계수(가중치)는 이전 시각 t에서의 가중치에 목표함수 J의 미분을 곱하는데 학습속도 a만큼 곱하고 더함. 이렇게 근사된 정책을 업데이트 하는게 폴리시 그레디언트
위의 식을 다르게 표현해보자 에피소드의 끝이 있고 에이전트가 특정상태 S0에서 에피소드를 시작하는 경우 목표함수는 S0에 대한 가치함수가 됨, 이때 목표함수의 정의는
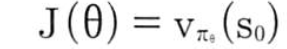
목표함수의 미분값은
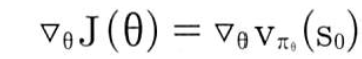
이 식을 다르게 표현하면 폴리시 그레디언트 정리라 표현

d(s)는 s라는 상태에 에이전트가 있을 확률(상태 분포), 이 식은 모든 상태에 대해 각 상태에서 특정 행동을 했을 때 받을 큐함수의 기대값
에이전트가 에핗소드 동안 내릴 선택에 대한 좋고 나쁨의 기준이 됨
위의 식을 조금 바꾸면

이걸 다시 쓰면

기대값의 정의는 확률 X 받은 값인데 이 식 또한 기대값의 한 형태라는 것을 알 수 있음
여기서 이 부분은 에이전트가 어떤 상태 s에서 행동 a를 선택할 확률

최종적으로 얻은 것은 목표함수의 미분값(경사), 기대값의 형태로 나타내는 목표함수의 미분은

근데 폴리시 그레디언트에서도 기대값은 샘플링으로 대체 가능, 결국 에이전트가 정책 신경망 업데이트하기 위해 구해야 하는 식은 이 식임

이 식을 구하면 정책 신경망 계수는 경사상승법에 의해 업데이트, 위에 나온 정책 신경망 업데이트 수식을 다시 쓰면 다음과 같음

REINFORCE 알고리즘
근데 폴리시 그레디언트에서 행동을 선택하는데 가치함수가 필요하진 않음, 에이전트는 정책만 가지고 가치함수 or 큐함수 가지고 있지 않음 그래서 위의 식에서 큐함수를 구할 수 없음
그래서 큐함수를 반환값 G로 대체해서 표현 --> 이게 바로 REINFORCE 알고리즘

에피소드가 끝날 때까지 기다리면 에피소드에서 지나갔던 상태에 대해 각각의 반환값을 구할 수 있음
즉, REINFORCE 알고리즘은 에피소드마다 실제로 얻은 보상으로 학습하는 폴리시 그레디언트, 몬테카를로 폴리시 그레디언트라 부름
참고 : 파이썬과 케라스로 배우는 강화학습
'강화학습' 카테고리의 다른 글
| [강화학습] 살사, 큐러닝 (0) | 2020.01.18 |
|---|---|
| [강화학습]다이내믹 프로그래밍 (0) | 2020.01.15 |
| [강화학습]벨만 방정식 (0) | 2020.01.15 |