sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기
4.3 Policy Iteration
일단 policy \( \pi \)는 더 좋은 policy \( \pi' \)를 만들기 위해 \( v_{\pi} \)를 사용해 개선되었고, 우리는 \( v_{\pi'} \)를 계산해서 더 나은 \( \pi'' \)을 만들기 위해 다시 개선할 수 있다. 따라서 다음과 같이 단조롭게 개선되고 있는 policy와 value function을 얻을 수 있다.

여기서 \( \overset{E}{\rightarrow} \)는 policy evaluation을 나타내고 \( \overset{I}{\rightarrow} \)는 policy improvement를 나타낸다. 각 policy는 이전의 것보다 strict improvement를 보장한다(이미 optimal인 경우를 제외하고). 왜냐하면 finite MDP는 한정된 policy의 갯수를 가지기 때문에, 이 과정은 한정된 반복횟수 내에 반드시 optimal policy와 optimal value function으로 수렴해야 한다.
이렇게 optimal policy를 찾는 방법을 policy iteration이라 부른다. 완전한 알고리즘은 아래의 박스에 주어진다. 반복적인 계산인 각 policy evaluation은 이전 policy의 value function으로 시작한다. 이는 일반적으로 policy evaluation의 수렴속도를 크게 증가시킨다(아마도 value function이 한 policy에서 다음 policy로 잘 변하지 않기 때문일 것이다).

Example 4.2: Jack's Car Rental
Jack은 전국적인 자동차 렌탈 회사의 두 곳을 관리한다. 매일 몇몇의 고객들이 각 지점에 차를 빌리기 위해 온다. Jack에게 빌려줄 수 있는 차가 있다면 그는 빌려주고 회사로부터 $10를 받는다. 만약 차가 없다면 사업은 망한다. 자동차는 반납한 다음날 렌트할 수 있다. 자동차가 필요한 곳에 있게 하기 위해 Jack은 밤 사이에 두 곳 사이에서 차를 이동시킬 수 있는데, 자동차당 $2의 비용이 든다. 우리는 각 장소에서 요청되고 반납되는 자동차의 수가 Poisson 랜덤 변수라고 가정한다. 이는 자동차의 수가 n일 확률이 \( \tfrac{\lambda^{n}}{n!} e^{-\lambda} \)임을 의미한다. 여기서 \( \lambda\)는 expected number이다. 첫번째, 두번째 장소에서 렌탈 요청 \( \lambda \)가 3,4 그리고 반납이 각각 3,2라고 가정해보자. 이 문제를 조금 단순화시키기 위해 각 장소마다 차량이 20대가 넘지 않는다고 가정하고(추가되는 자동차는 렌탈 회사에 반납되어 문제 없다) 밤에는 최대 5대의 자동차까지 다른 장소로 이동시킬 수 있다. 우리는 discount rate \( \gamma =0.9 \)로 하고, 이 문제를 continuing finite MDP로 공식화한다. 여기서 time step은 날짜, state는 하루가 끝날 때 각 장소의 자동차 수, 그리고 action은 밤동안 두 장소에서 이동한 차의 숫자이다. 그림 4.2는 어떠한 차도 움직이지 않은 policy에서 시작해서 policy iteration에 의해 발견된 policy들의 순서를 보여준다.
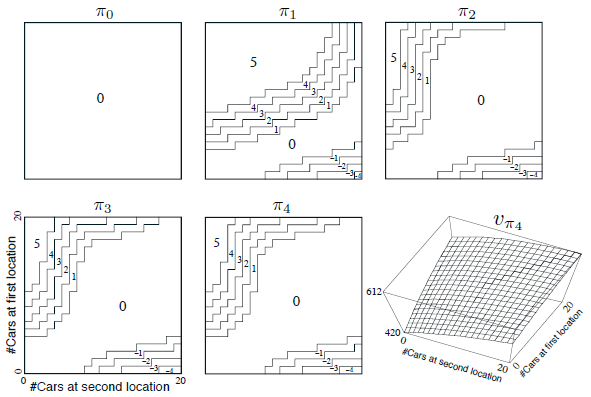
첫번째 5개의 도표는 하루가 끝날때 각 장소의 자동차 수에 대해 첫번째 위치에서 두번째 위치로 이동할 차들의 수를 보여준다(음수로 표시된 것은 두번째 장소에서 첫번째 장소로 이동한 것을 나타낸다). 각각의 연속적인 policy는 이전의 policy보다 strict improvement를 이뤘고, 마지막 policy는 optimal이다.
Policy iteration은 Jack의 자동차 렌탈과 그림 4.1의 예에서 설명된 것 처럼 종종 놀라울정도로 적은 iteration으로 수렴된다. 그림 4.1의 좌측하단 도표는 균등한 random policy에서 value function을 보여주고, 우측 하단 도표는 이 value function에서 greedy policy를 보여준다. Policy improvement 정리는 이런 policy들이 original random policy보다 더 나아지는 것을 보장해준다. 하지만 이경우, 이런 policy들은 더 나은 것이 아니라 optimald이며, 최소한의 단계로 terminal state로 진행한다. 이 예제에서 policy iteration은 단 한번의 iteration 후에 optimal policy를 찾을 것이다.( 여러 exercise 문제들은 다른 곳에 작성)
4.4 Value Iteration
Policy iteration의 단점 하나는 각 iteration이 policy evaluation을 포함한다는 것이다. 이는 state 세트를 통해 여러번의 sweep을 필요로하는 반복적인 계산일 수 있다. policy evaluation이 반복적으로 수행되면, \( v_{\pi} \)로 정확히 수렴되는 것은 오직 제한된 상황에서만 일어난다. 그렇다면 정확한 수렴을 기다려야할까? 아니면 그에 못 미치게 할까?
수정중
'강화학습 > Reinforcement Learning An Introduction' 카테고리의 다른 글
| Reinforcement Learning 책 읽고 공부하기(4) (0) | 2020.05.22 |
|---|---|
| Reinforcement Learning 책 읽고 공부하기(3, Exercise2) (0) | 2020.03.12 |
| Reinforcement Learning 책 읽고 공부하기(3-3) (0) | 2020.03.12 |
| Reinforcement Learning 책 읽고 공부하기(3-2) (0) | 2020.03.09 |
| Reinforcement Learning 책 읽고 공부하기(3, Exercise) (2) | 2020.03.09 |