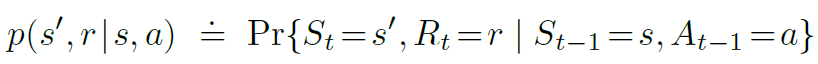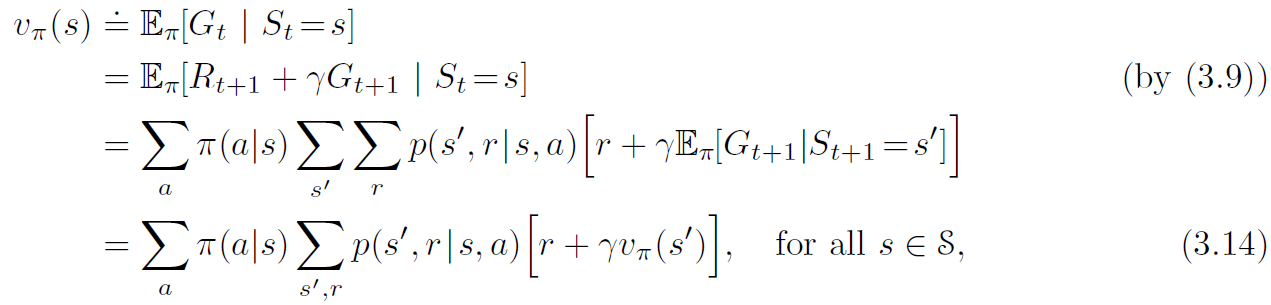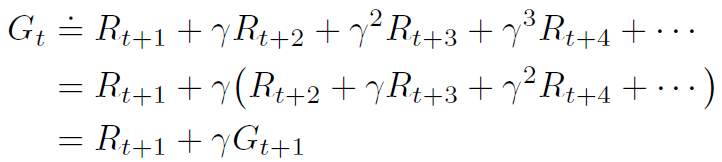이번 구현에도 역시 OpenAI의 FrozenLake-v0를 이용해서 구현해보자 몬테카를로 예측의 경우 에이전트가 환경에서 실제로 받은 reward들의 각 state에서 return을 계산해 그것들의 평균으로 참 가치함수를 예측하는 것임. 이제 이 이론을 가지고 코드를 짜보자 import gym import numpy as np import random GAMMA=0.9 EPISODES=1000 POLICY = [0.25, 0.25, 0.25, 0.25] THRESHOLD = 1e-20 얼음호수 예제의 경우 action이 4개이고 각 action을 할 확률 그러니까 policy는 모든 action이 동일하다고 가정. 그리고 이 policy에 대한 예측을 시작. env = gym.make('FrozenLa..