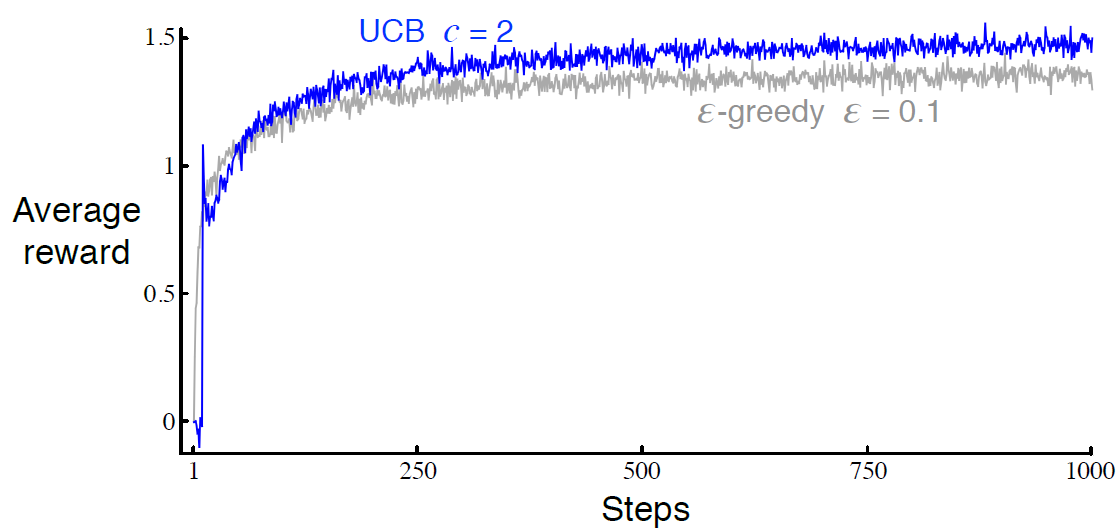
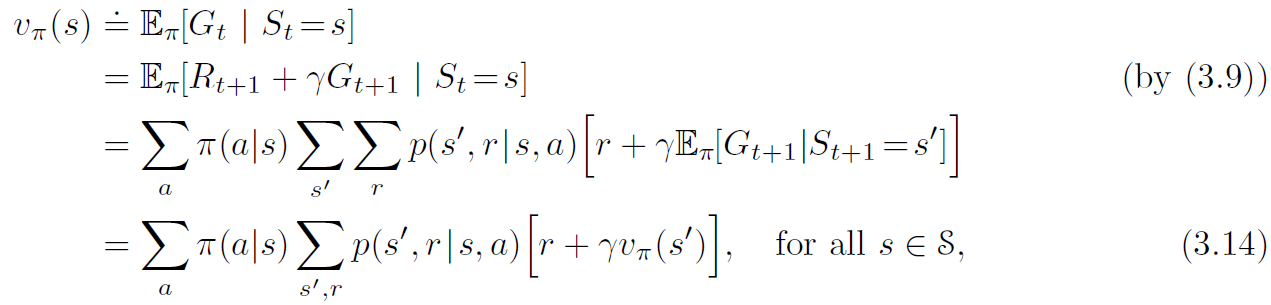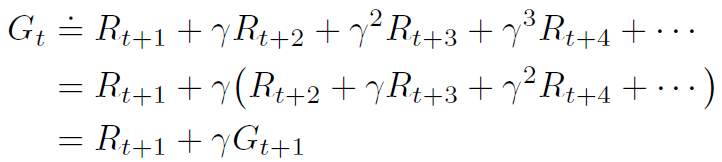sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기 3.5 Policies and Value Functions 거의 모든 강화학습 알고리즘들은 에이전트가 해당 state에 있는게 얼마나 좋은지 계산하는 value function(state의 function 또는 state-action쌍)을 포함한다.(또는 주어진 state에서 주어진 action을 하는게 얼마나 좋은지). "얼마나 좋은지"는 미래 reward의 기대값, 즉 expected return으로 정의한다. 당연하게도 미래에 받을 것이라 기대하는 reward는 에이전트가 어떤 action을 할지에 달려있다. 따라서 value function은 어떻게 policy라 부르는 어떻게 acting해야..