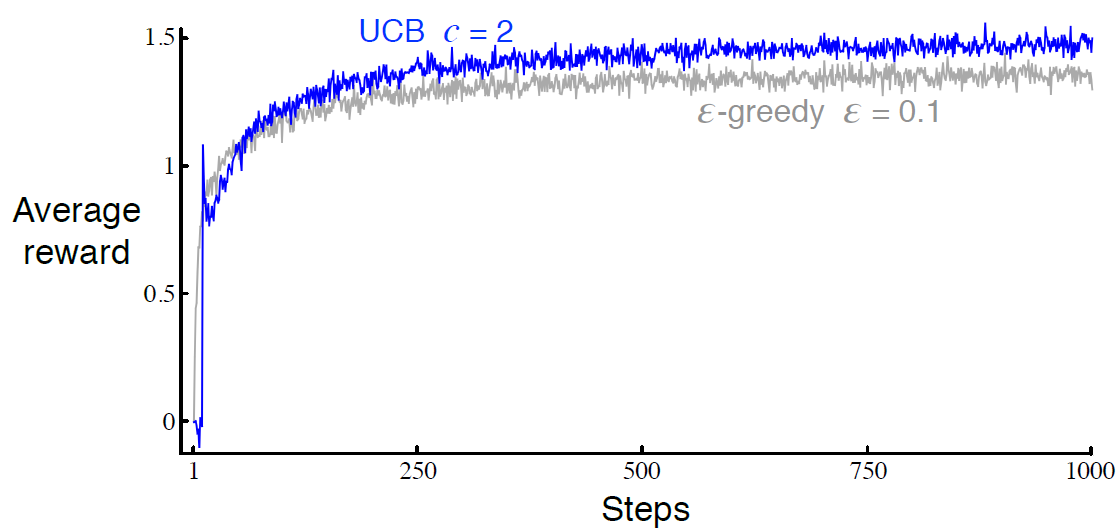
sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기 2.7 Upper-Confidence-Bound Action Selection action-value 추정치의 정확도가 항상 불확실하기 때문에 exlporation은 필요하다. \( \epsilon \)-greedy action 선택은 non-greedy action을 선택할 수 있게 한다. 실제로 optimal일 가능성에 따라 non-greedy action을 선택하는 것이 좋다. 여기서 추정치가 최대치에 얼마나 근접한지, 그리고 그 추정치의 부확실성을 고려해 action을 선택한다. 이렇게 action을 선택하는 하나의 효과적인 방법은 아래와 같다. $$ {A}_{t} \doteq \left[ {..