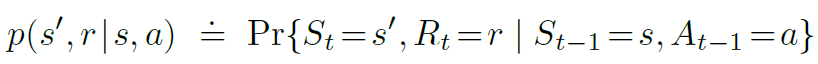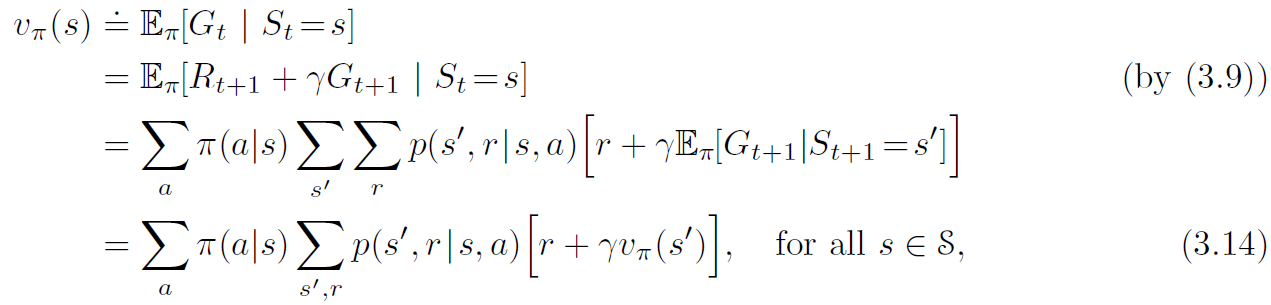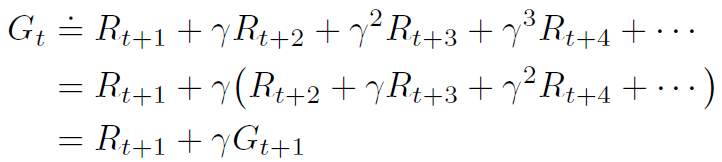sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기 Dynamic Programming Dynamic programming(DP)는 MDP로 환경의 완벽한 모델이 주어졌을 때 optimal policy를 계산하기 위한 알고리즘들의 collection이다. 전통적인 DP 알고리즘들은 완벽한 모델의 대한 가정과 엄청난 계산량 때문에 강화학습에서의 활용성은 제한되었다. 하지만 이론적으로는 여전히 중요하다. DP는 이 책에 나머지 부분에 설명되는 방법들을 이해하기 위한 필수적인 기초를 제공해준다. 사실 이러한 모든 방법들은 계산을 덜하고 환경에 대한 완벽한 정보없이, DP와 동일한 효과를 달성하기 위한 시도들이라고 볼 수도 있다. 우리는 보통 환경을 fini..