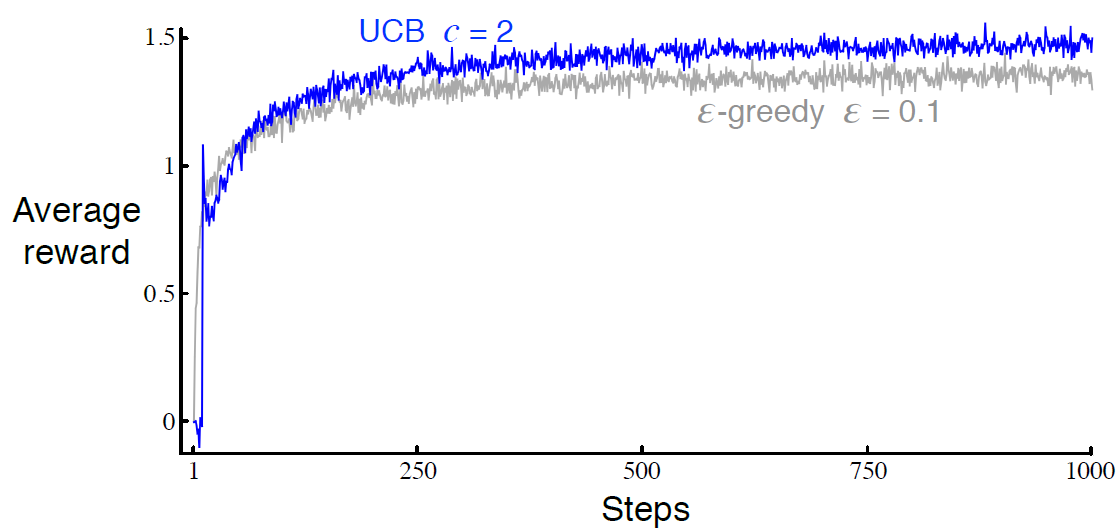
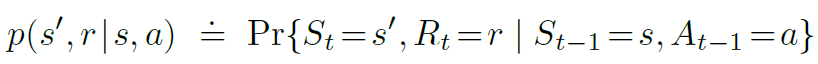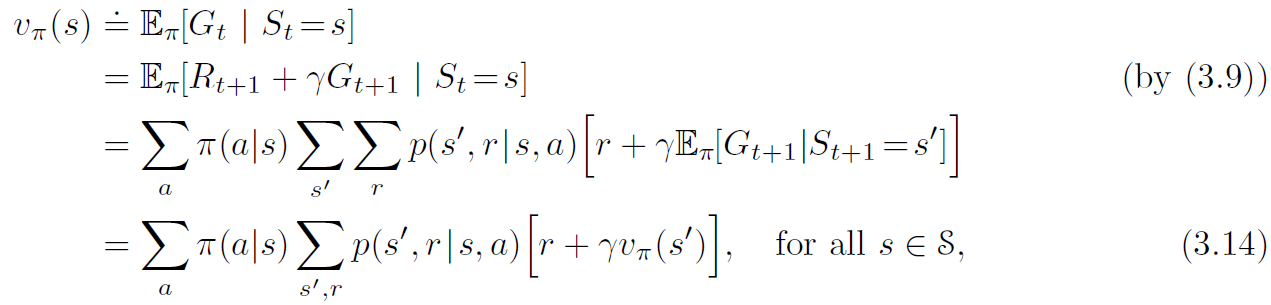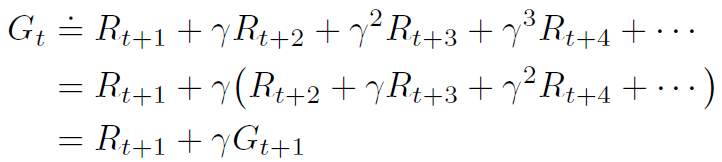sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기 4.3 Policy Iteration 일단 policy \( \pi \)는 더 좋은 policy \( \pi' \)를 만들기 위해 \( v_{\pi} \)를 사용해 개선되었고, 우리는 \( v_{\pi'} \)를 계산해서 더 나은 \( \pi'' \)을 만들기 위해 다시 개선할 수 있다. 따라서 다음과 같이 단조롭게 개선되고 있는 policy와 value function을 얻을 수 있다. 여기서 \( \overset{E}{\rightarrow} \)는 policy evaluation을 나타내고 \( \overset{I}{\rightarrow} \)는 policy improvement를 나타낸다. 각 ..