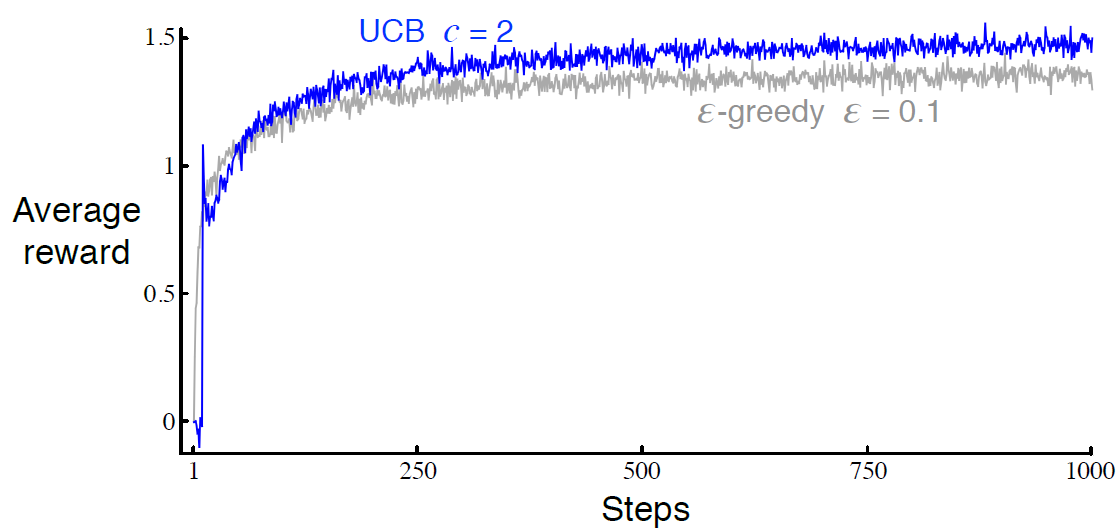
sutton 교수의 Reinforcement Learning An Introduction을 읽고 공부하기 챕터 2에서 본 연습문제들 풀어보기 Exercise 2.6 Mysterious Spikes 그림 2.3의 결과는 10-armed bandt 문제에서 각각 임의로 선택한 2000개 이상이므로 신뢰할 수 있어야 한다. 왜 진동과 스파이크가 optimistic 방법의 초기에 나타났는가? 다른말로는 왜 이 방법이 average 방법에 비해 초기에 성능이 더 좋거나 나쁜가? 일단 가져와 본 그림 2.3 Optimistic greedy에서는 초기값(initial estimate)에 의해 평향되어 있음. sample-average 방법은 이 편향이 사라지는데 constant average에서는 편향이 영구적인데 ..